Paul Hickey, our Director of Digital Solutions, recently shared his insights about life event trigger marketing, and how businesses can and should be using it in Business Computing World. We’ve highlighted the key elements of his article below.
Life event trigger marketing is about identifying when people are going through those big events in their lives that lead to changes in their buying behavior – and using this knowledge to communicate with them at exactly the right time, with exactly what they need. In life event trigger marketing, you need to have factual data that shows you exactly where someone is on that life event journey – for instance, if their house is ‘sold subject to contract’, you know that they are moving home imminently. For a bed manufacturer, for instance, this is invaluable knowledge to decide on the timing and message of communications. And for the consumer, it means they will be receiving very useful information and offers to help them make timely decisions.
Life event trigger marketing is, therefore, a way of understanding the context of someone’s behavior – why they are doing what they are doing. And this is incredibly powerful. For example, if a department store identifies a woman aged 45-55 is searching for crockery and bedding then that’s interesting. However, if they also know they have a child heading to university then that’s much more interesting! It means that the type of crockery and bedding they should promote needs to be low-end rather than high-end – plus they can identify many other cross-selling opportunities relating to this life event; from student banking deals to posters.
The context provided through life event information is key in creating the right messaging. Highly personalized mailings and timely display advertising focusing on trigger touchpoints can significantly increase results and develop brand loyalty making a customer feel valued and understood.
The secrets to success
While life event trigger marketing is unlikely to become the sole marketing approach for any brand, there are a significant number of companies who would benefit from adding it into the marketing mix to boost overall campaign effectiveness. Interestingly, it’s not just obvious sectors, such as furniture and DIY either. For example, moving home often leads to the purchase of a holiday, as people consolidate loans and book a much-needed trip post-move. So for any marketer looking to bring a life event approach into their marketing mix, what are the three most important points to remember?
- Data – recent data is vital, as is factual, not inferred data
- Content – communications must be contextually relevant in terms of both timing and messaging
- Omni-channel – the consumer journey is no longer linear; know how to target consumers when it matters most.
These factors are beneficial to any marketing strategy but should be seen as essential for a successful life event campaign. The right data crafted into emotionally relevant content can empower your company to reach consumers at the exact time when they need your services most.
To read the full article from Business Computing World, click here.
To have a free consultation from us, click here
It’s been over 2 years now since we launched MoverAlerts.co.uk, our revolutionary online portal providing B2C lead generation to the removals and storage sector.
If you’re looking to tap into a captive market of relevant leads or to find a solution to better segment potential customers, MoverAlerts.co.uk can help. We also work with our clients to produce tailored marketing campaigns on your behalf.
But don’t just take our word for it! Since launching in July, we’ve received some great feedback about the portal. Here’s what some of our customers have to say:
“Very straightforward to use – you get the email to say it’s ready, login, open it up and convert it to a word document using a mail merge and then it’s out the door. Very effective and straightforward and works for us!”
– Darren Bosher, MD, Steve Frieze Removals
“Really easy and so simple to log in after receiving the email to download your weekly data. The site looks and feels very fresh.”
– Jamie Wells, MD, Better Removals
“We continue to have a very high level of satisfaction with the leads supplied to us. We started to use the MoverAlerts service in September 2013 and three years later it still exceeds our expectations, providing a high service at such a reasonable cost. May the relationship continue for many more years.”
– Graham Ham, Office Manager, Manns Removals and Storage
MoverAlerts: What are they and how do they work?
Specialists in producing and delivering home mover engagement triggers, TwentyCi provide home mover contact data – or MoverAlerts – for any property listed for sale, under offer, or recently sold in the UK. TwentyCi data is drawn from a database of over 1.2 million postal records accounting for 99.6%* of home movers across the UK.
To see all the benefits for yourself, visit MoverAlerts.co.uk now and email one of the team.
The British Retail Consortium (BRC) recently issued a press release that announced a record reduction in retail unemployment, with hours worked has gone down by 4.2% compared to the same time last year. According to the BRC’s chief exec, Helen Dickinson OBE, this is due to a technological revolution in retail. TwentyCi’s Commercial Director, Nick McConnell, discusses in a new article for Retail Tech News, some of the solutions for this new landscape.
Nick suggests that the traditional bricks and mortar high street and shopping center retailers are in a period of change, not only due to technological change but also the weaker pound, rise of inflation and squeeze of discretionary spend available. Similarly, the “always on” availability of online stores provides choice and convenience as a new standard has put pressure on these retailers.
So what’s the solution to stop the physical store becoming a thing of the past? Today’s retailer is more empowered than ever to make smart decisions about store locations, ranges and more. This should be combined with clever and relevant marketing; the stores should be using available data to communicate to consumers effectively. Big data underpins the ability to understand the sociodemographic of the store catchment and, with it, the ability to determine the appropriate ranges. Additionally, with the proactive collection of customers’ details through online purchases, collections, refunds, or loyalty programmes the retailer can ascertain further insight into their customer profiles together with the distance traveled and the reason for coming to the store.
The physical store isn’t dead, but it does need to be optimized. Nick describes recent findings from work with a national furniture retailer that customers were choosing to drive past their nearest store in favor of one located in a leisure and shopping destination: “This is reflected in the rise of ‘hero stores’ at the center of shopping destinations such as the House of Fraser at Rushton Lakes or the new John Lewis at Westgate Oxford. Technology can provide retailers with the insight to allow them to reduce the size or number of stores, and optimize the potential of the customers available.”
To read the full article, click here. To read more about our work with other retailers click here.
Objectives:
Deploy an application with a custom environment to Google Cloud
Prerequisites:
Folk and clone this repo: https://github.com/hangnhat57/compute-engine-101/
Open Terminal and cd to the folder you’ve just cloned
First, let’s try to run the app on a local machine to verify it has worked:
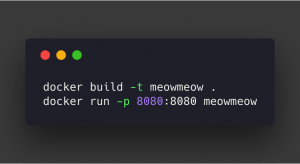
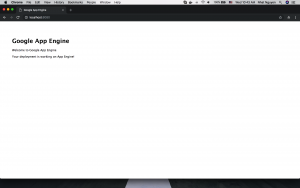
Open your browser and navigate to http://localhost:8080, you’ll see something like this:
This application is serving inside a container which was customized from scratch:
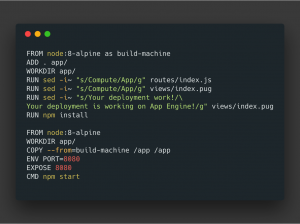
To deploy a custom container to App Engine, we have to use Google App Engine Flex – Custom Environment. By default, App Engine will serve container application in port 8080, so remember when you create an image.
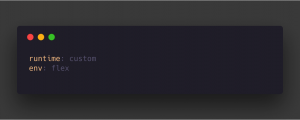
App.yaml file will look like this :
Now, on the terminal, start a command:
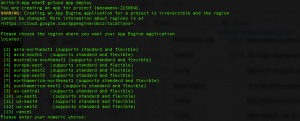
If this is the first time you using App Engine for the current project, Google will ask you for the region of App Engine service:
Select the region you want and wait until it finishes. Then use this command to view your app on the public:
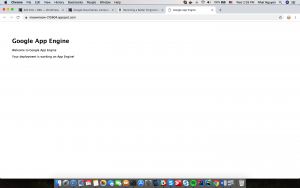
A browser would automatically open and navigate to your app:
Have you read the previous post of the Google Cloud Series? Make sure you check it right now
Comment below or email us via contact@twentyci.asia if you have any question or want to have free consultation!
Nhat Nguyen
In the last post, we had introduced to you the two main way to store data on a blockchain. Today, we’ll discuss platforms that support them.
Any supporting platforms?
There are few projects that focus on data storage right now. Most are built around decentralized file storage, which includes documents.
One project that is focused specifically on documents, particularly signed documents, is Blocksign. This uses the hash method. A user will sign the document and send it to Blocksign, where it is then hashed, and the hash is stored on the Bitcoin blockchain. We must warn users that Blocksign has not recently updated their site, and we would encourage further research before use.
Two cryptocurrency projects designed for decentralized storage more generally are Siacoin and Storj.
Siacoin does not use a blockchain for any form of storage. Instead, their distributed network stores an encrypted version of your document. The Siacoin network is comprised of hosts who provide and clients who desire storage. Clients and hosts agree upon contracts detailing the commitments made by the storage providers. Sia’s own proof of work blockchain stores these contracts.
Storj, on the other hand, is closer to the hash model. A hash of the document is stored within a hash table on-chain. Additionally, its distributed network also stores your document. Unlike Sia, however, Storj runs atop the Ethereum blockchain rather than its own.
Cryptyk, an enterprise-focused platform to store documents, uses a blockchain more distantly than all of the above. You do not store any documents or hashes on-chain. Instead, a distributed cloud system stores the documents. The platform only uses a blockchain to manage and referee document access and sharing.
Document blockchain storage is a sector of this industry moving forward steadily. Right now, we are waiting to see what role blockchains will play in storing documents. Fortunately, the competition among projects is furthering our understanding of this promising use case.
Please share your thought with us in the comment below
Hung Le
When you get a new project from a partner/client (a maintenance project), how do you know the quality of the new project’s code? Has there been a core hack or not? Verifying whether the core code of Magento has changed or not is a part of the Audit code task. Here, I will write the steps which I do to check whether the code of Core Magento has been changed or not.
First of all, we need to know why we have to verify whether the core of Magento is changed or not.
As you know, Magento changes a lot, and Magento release new versions frequently to update functions, fix bugs, improve security, etc. So each time Magento releases a new version we have to update our projects to the latest version of Magento to get the latest features and improve the security of our web site.
Each update of the Magento core is likely to change the code, and changes will be overridden when we update Magento to a new version. This could cause the site to lose functions which we made by changing the previous code in Magento’s core.
To avoid this happening we have to make sure that the core is not changed before we start implementing new functions/features for a maintenance project.
To verify the core code we need to compare the core code of a fresh Magento version (an original version downloaded from Magento) and the core code of our maintenance project.
First, we have to check the Magento version of maintenance project. In this article, I will use Magento 2 as a demo to show verify steps.
- Step 1: Get a used version of Magento – To get a version of Magento 2 you just need to check composer.json in the web root of the project:
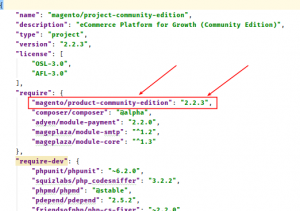
-
- Step 2: Get fresh Magento version from Magento site: Go to https://magento.com/tech-resources/download then select ‘Release Archive’ then choose used version. In my case, it’s version 2.2.3. I download then extract to /var/www/html/magento223
-
- Step 3: Get code of maintenance the project to your local: In my case, I place the code of maintenance project at /var/www/html/my-maintain-project
- Step 4: Compare the core code of fresh Magento 2.2.3 with my-maintain-project using Beyond Compare
- A note about Beyond Compare – this is comparing tool which helps you detects different points between two files or two directories
- Open Beyond Compare then select ‘Folder Compare’ function:

-
- Then select vendor/magento directory of two fresh Magento and your project as below:
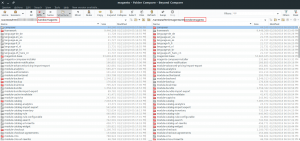
It will show different things between the two directories vendor/magento.
-
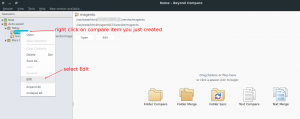
- One thing we need to update for Beyond Compare to make it show more clearly what’s different between two directories as below
- Click on the Home icon of Beyond Compare then right click on your item in session as below:
- One thing we need to update for Beyond Compare to make it show more clearly what’s different between two directories as below
-
-
- Then select Comparision tab and select some options as below:
-
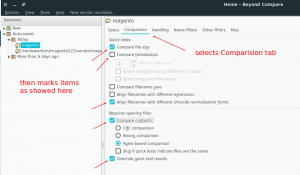
-
-
- Now you will see a much better result in two directories:
-
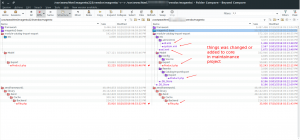
With this result, we can see whether the core of the maintenance project is hacked or not so we will have to find a solution to fix it before we start adding new functions.
In my case, I see my project has some changes in Magento core files. So I have to check these changes then migrate them to a custom module to keep the changed functionality and then revert the core files to the original code.
You can apply the same for Magento 1 when you do an audit for a Magento 1 project.
Thanks for reading. Please leave a comment below if you have any question.
Vong Tran
At TwentyCi, we recognize the importance of omnichannel programmes as an extremely important marketing approach. And as a concept that is likely to only continue to grow in the coming years. With this significance in mind, Paul Hickey, our COO, was recently asked to provide his best tips for omnichannel marketing. Read on for this top five.
1) Ensure your customer data is correct and up to date
Recency of data is of the utmost importance and it should be factual, not inferred if you want to ensure your communications are fully on point.
2) Make your content relevant
Ensure communications are contextually relevant in terms of both timings and messaging to optimize their impact.
3) Understand your customer journey
In omnichannel the consumer journey is no longer linear so you need an understanding of where your customers are so that you reach them in the right way.
4) Have a 360° view of your customers
Take a holistic view of your customers rather than looking at what they are doing in isolation. Only then can you make fully informed decisions about offers, messaging and timing.
5) Don’t be creepy!
Data enables us to gain a rich understanding of the people we are targeting, but be careful how you use it. The approach will depend on the brand and the product/service being promoted. A homemover will undoubtedly be in the market for new furniture, carpets or DIY products and will be grateful for the communication. However, make sure you use your knowledge to be relevant with a tone that is not intrusive. For instance, we would never advocate saying ‘we know you are having a baby’!
To find out more about how TwentyCi can help you prepare for some of these challenges and opportunities, including putting the consumer into context with our homemover data please leave a comment below or email contact@twentyci.asia
Hi everyone,
This is Amy from Earth planet. I used to work as a Business Analyst (BA) for a couple of years and for the rest of my life I would never forget that miserable duration of time. And why do I use the word “miserable”? Because my starting point for this job is way more backward than others in the IT industry: Technical knowledge is at a zero scale. So I wrote this post to help people who have the same background as me or people who intend to pursue BA job, to decide your career path in the future.
Lesson 1: Are you ready to learn a language which is not from Earth?
I’m sure that you’ve already learnt at least one foreign language before at school. How was that? I believe that most people would say it’s not easy at all (and it’s a nightmare for me, FYI). We have the Latin system and logographic system language, but the one that I’ve been working on should be called Alien language.
This is the first price that you need to pay when you start working as a BA without technical support and business domain knowledge. You will see that you’re the only one in the team who doesn’t know what the hell everyone is talking about. Even if you understand each and every single word that they’re saying, but your brain cannot work properly to decode any combination of those. So what should you do in that case? When your boss just assigned to you a project on the second day at work? Well, my angel on the left shoulder screamed “Run for your life! You idiot!” but my demon on the right shoulder said, “Let’s kill the Alien and take its brain”. In the end, the demon won and I started a horrible year of working and learning at the same time.
God blessed me since I got through several of small-sized projects and still survived after a year. It’s kind of interesting when you look back to your very first user stories and use cases when you already have 1 year of experience. Because this is the moment you see how clumsy you were when handling a user story, but you also realize how much you have earned from your job.
Lesson learnt: Don’t be afraid of anything, even it’s something that you haven’t seen before. As long as you’re a BA, you’ll have to switch project/domain many times depending on the needs of clients.
Lesson 2: Wake up! You are not the center of the world!
The ugly truth is that nobody will actually consider your pieces of advice if you’re the newbie in a project, even if you graduated with a high grade from the university. In my case, they were listening to my comments very carefully, and then quickly turned them to invalid ideas due to dozens of facts. Your team would appreciate very much if you’re able to provide something from your previous experience which can handle the problem they’re dealing with. So please don’t lose your confidence in such cases because it didn’t show that you’re wrong. It just proves that you still need to catch-up a lot of things and you must get to the point where you can make impacts to other members in the project.
Lesson learnt: You cannot go directly from A to Z in a day. Adaptation is a must-have step to take.
(To be continued)
See you guys in Part 2! Bye Bye!
Amy Do
To continue the Storing Data on the Blockchain series, this post will discuss the storing method. If you haven’t read the first post yet, let’s catch up right now
The Different Ways to Store Data on a Blockchain
There are two main ways you might choose to store data on the blockchain. One option is to store the entire document itself on-chain. Alternatively, you can store a hash of it on the blockchain.
Storing the Entire Document
Storing a whole document on-chain is possible with certain blockchains, however, it is rarely a good idea. Due to the huge data demands, unless it is a very small file or of extreme importance, you would be better choosing another method. If you wanted to store the document on Bitcoin, then you first have to compress it and then format it into a hexadecimal form.
The problem with storing whole data on a blockchain is because of something called access latency. This just means how long it takes network users to upload and download files, such as documents. Fully decentralized public blockchains have thousands of nodes. Unfortunately, the benefits that come with this number of nodes also results in a corresponding increase in latency. Any file storage, including documents, needs to have low latency otherwise the system becomes clogged up, slow, and expensive to use.
A hybrid strategy can also make sense. This would involve storing a small part of the document, perhaps the signatures, as well as the document hash on-chain. This allows you to maintain decentralization and full transparency of the parts that absolutely require it while maintaining a cap on the data load.
Storing a Hash
The most efficient method is to store a data hash on-chain while keeping the whole document elsewhere. The document could be stored in a centralized database or on a distributed file storage system. You would put the document through a secure hash algorithm like SHA-256 and then store the hash in a block. This way you save a huge amount of space and cost. Additionally, you will be able to tell if someone tampers with the original document. The change in input would result in a completely new hash value, different from your original document.
Hash values are far smaller than whole documents and so are a vastly more efficient blockchain storage method. It also scales efficiently. For storing multiple documents, you can put the hashes into a distributed hash table, which you then store on-chain. The downside is that the storage of the original document is not decentralized nor necessarily publicly visible.
What do you think about Storing Data on Blockchain?? Feel free to discuss with us
Hung Le
In the last post, I introduced the concepts of Vue.js. Today, we start to code and set up a project. First, we create a root folder named “vblog”.
-
Backend
We use Laravel (here I use the latest version is 5.7)
In the root folder, run command to create a project with “server” is the project name:
Laravel new server (noted: you have to install the Laravel installer first, the document here )

Now we have the folder structure below:
Then in Laravel project, we install some new packages to support API:
Run command: composer require barryvdh/laravel-cors
That’s enough for the server now, we will use it later
Now we go to set up the frontend (Vue.js) using Nuxt framework
-
Frontend
In the vblog folder, we create a Nuxt project named “web-app” using yarn
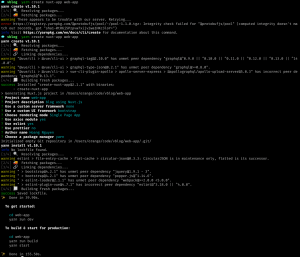
While creating, it will ask you some questions.
Here I choose below answers:
- Project name: web-app
- Project description: blog using Nuxt.js
- Use a custom server framework: none (because we use Laravel as the server)
- Use a custom UI framework: bootstrap (because it’s popular, easy to use)
- Choose rendering mode: Single Page App
- Use axios module: yes (we will use axios to call API)
- Use eslint: yes
- Use prettier: no
- Author name: Huy Hoang
- Choose a package manager: yarn
Now we have the code folder structure like this:
Then in Nuxt project, we install some packages: jquery, node-sass, sass-loader, vue-notification, @nuxtjs/dotenv
Noted: jquery is not suggested using in Vue. But some package required it, so we still need to install jquery. But we will not use jquery in our code.
Now we try to run the project in a web browser.
Start server by running the command: yarn run dev then open URL http://localhost:3000/ in Chrome

We’ve finished setting up the project with Laravel as backend and Nuxt.js as frontend.
In the next post, we will build our web layout and custom the loading effect automation whenever URL router change, and add custom notification. Stay tuned!